Synthetic Biology: A Brief Overview
Raymond LeClair
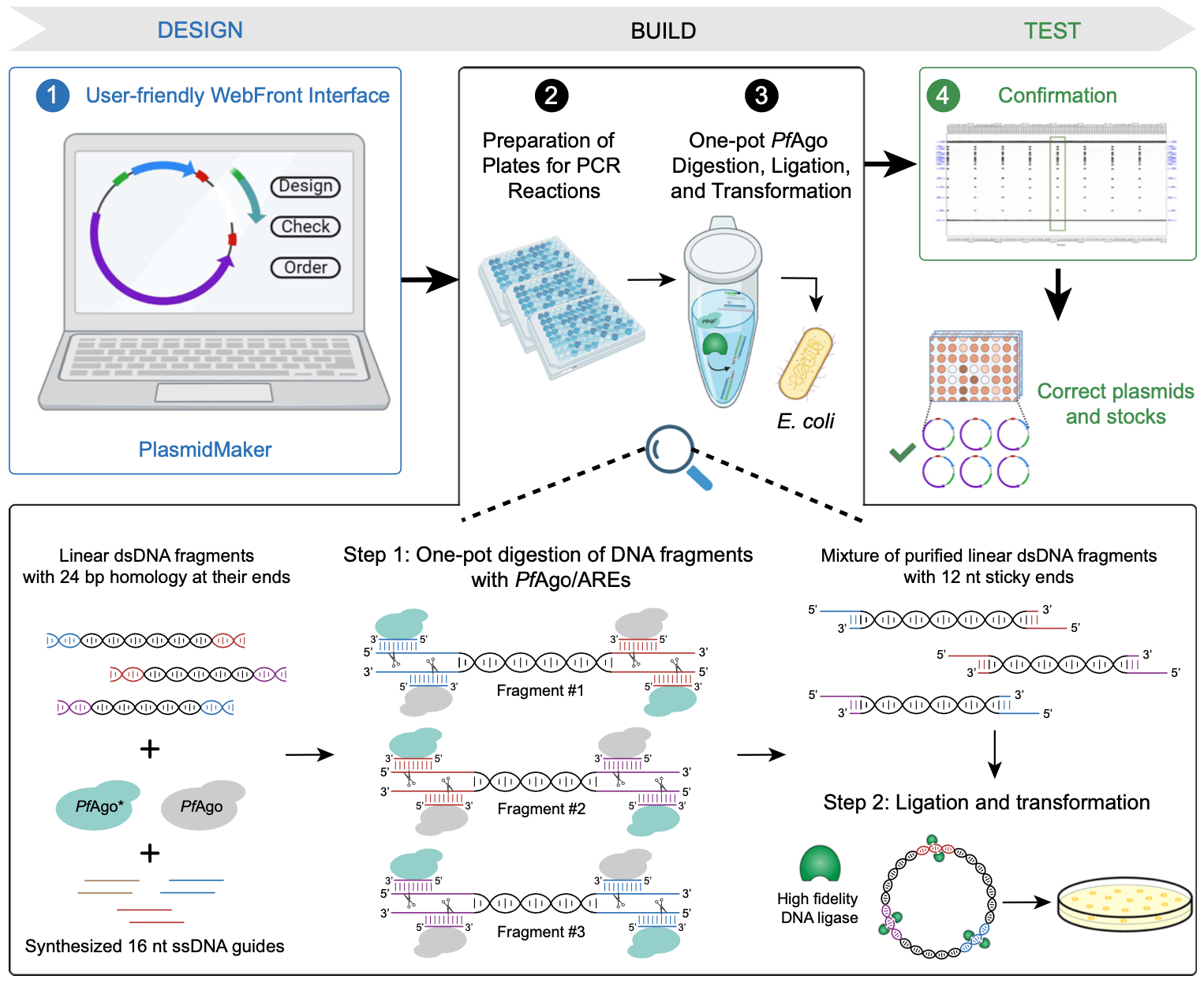
Reproduced from Enghiad, B., Xue, P., Singh, N. et al. PlasmidMaker is a versatile, automated, and high throughput end-to-end platform for plasmid construction. Nat Commun 13, 2697 (2022).
What comes to mind when you read the phrase “synthetic biology”? Do you think of those little creatures created by the quirky fellow in “Blade Runner”? Or, perhaps you think of genetically modified mosquitoes designed for “gene drives”' to eradicate malaria. Or, designer yeast with genes modified to produce useful industrial compounds. I tend to think of a single cell organism, living, with DNA entirely selected, nucleotide by nucleotide, by a human. Well all of these, with the exception of the first, are, indeed, examples of “synthetic biology”.
Here we present a definition of synthetic biology, describe its connection to DNA sequencing, and bioinformatics, and describe Springbok’s connection to the field.
What is synthetic biology?
Here is an authoritative definition:
“Synthetic biology is the design and construction of new biological parts, devices, and systems, and the re-design of existing, natural biological systems for useful purposes."
Absent from that definition is the creation of a living organism with DNA designed by a human, although the genome for such an organism does exist, allowing that design was created by computer (which, of course, does imply a human coder), and started with the genome of a living organism. Specifically, in 2019 scientists at ETH Zurich created the world’s first fully computer-generated genome of a living organism, Caulobacter ethensis-2.0, although an organism living with this genome does not exist.
The first identifiable use of the term “synthetic biology” in Stéphane Leduc’s 1920 publication Théorie physico-chimique de la vie et générations spontanées. Progress in the field, however, required a convergence of advances in chemistry, biology, computer science, and engineering that occurred over the last four decades. I explore this convergence next.
Connection to DNA Sequencing and Bioinformatics
Advances in chemistry, biology, computer science, and engineering have resulted in dramatic cost reductions in DNA sequencing and synthesis, sophisticated tools for gene editing, and purpose built computational tools. DNA sequencing and the computation tools developed to process the resulting avalanche of data first captured my imagination. And an avalanche of data it has been! The National Human Genome Research Institute predicts that genomics research will generate between 2 and 40 exabytes of data within the next decade, with roughly 2 to 40 billion gigabytes of data now generated each year. Furthermore, the development of these computational tools have given rise to a discipline commonly referred to as bioinformatics. I provide a short history of these developments below.
A very short history of synthetic biology, DNA sequencing, and bioinformatics
Here I collect a few milestones in the history of synthetic biology, DNA sequencing and bioinformatics drawn from various sources (see: here, here, and here) to give a sense of the history. Though, being recent, the history presents a complicated, and uncoalesced story.
1950–1970: Protein analysis provides the starting point for bioinformatics.
1960s: Restriction Enzymes – Arber, Nathans and Smith discover restriction enzymes which cleave DNA into fragments at or near specific recognition sites. The discovery enables the creation of recombinant DNA, that is, DNA created by artificially combining constituents from different organisms. Arber, Nathans and Smith won the 1978 Nobel Prize in Physiology or Medicine for the discovery.
1970: First method for determining DNA sequences – Ray Wu at Cornell University established the method using a location-specific primer extension strategy.
1970–1980: Bioinformatics shifts from protein to DNA analysis.
1972: First technology for isolation of DNA fragments – Paul Berg developed the technology, before which, phages or virus DNA was available for sequencing.
1977: Sanger sequencing – Frederick Sanger adopted the primer-extension strategy to develop more rapid DNA sequencing methods at the MRC Centre, Cambridge, UK.
1980–1990: Bioinformatics embraces the free software movement.
1987: First commercial, automated DNA sequencing machine – Applied Biosystems marketed the ABI370 in the US.
1988: Polymerase chain reaction (PCR) – Mullis et al. published in Science DNA amplification by PCR using a thermostable DNA polymerase.
1990: The Human Genome Project formally began.
1990–2000: Genomics, structural bioinformatics and the information superhighway
1998: Bridge amplification – Eric Kawashima, Laurent Farinelli and Pascal Mayer developed a ‘Method of nucleic acid amplification’ at the Geneva Biomedical Research Institute.
2000: The Human Genome Project published a ‘rough draft’ of the human genome.
2000: Lynx Therapeutics Company launched the first Next Generation (after Sanger) Sequencing (NGS) technology, called Massively parallel signature sequencing (MPSS).
2000: Synthetic Biological Circuits – Two papers in Nature reported a genetic toggle switch and a biological clock, by combining genes within E. coli cells.[]
2000–2010: High-throughput bioinformatics
2004: Pyrosequencing technology – 454 Life Sciences marketed a new generation pyrosequencing technology, called the Roche GS20.
2012: CRISPR-Cas9 – Charpentier and Doudna publish in Science the programming of CRISPR-Cas9 bacterial immunity for targeting DNA cleavage. This technology greatly simplified and expanded eukaryotic gene editing. Charpentier and Doudna won the 2020 Nobel Prize in Chemistry for this work.
2014: Illumina establishes effective monopoly – Illumina launched a new technology, called HiSeq X Ten Sequencer, and announced that it had effectively monopolised the DNA sequencing industry, holding 70% of the market for DNA sequencers and accounting for over 90% of all the DNA data produced globally.
2019: The Nation Human Genome Research Institute reported that the price of sequencing a complete human genome was $942, beating Moore’s Law prediction.
The dominance Illumina achieved in the DNA sequencing market illustrates the complexity of this recent history. In order to achieve 70% of the market Illumina acquired fifteen firms, and merged with two, over a 10 year period. It was not the case that a single breakthrough technology provided the foundation for their success. As a further illustration, other DNA sequencing technologies exist, or are being developed. Notable among these are the so-called third generation technologies such as the Single Molecule, Real-Time (SMRT) Sequencing technology developed by PacBio, or the nanopore sequencing technology developed by Oxford Nanopore Technologies. More on these technologies will need to wait until a later post.
Springbok’s connection to bioinformatics
Use of DNA sequencing data produced by Illumina devices has become widespread. Consider, for example, Addgene. A nonprofit repository created to help scientists share plasmids, Addgene improves access to these materials and related information to accelerate research and discovery. During their quality control process, Addgene verifies all plasmids using short-read technology to ensure that only high-quality data and reagents are shared with the scientific community.
However, short-read technologies require complex algorithms to assemble de novo (or piece together without a reference) the reads into the single character string that is the target DNA sequence. And de novo assembly of plasmids presents unique challenges, primarily due to the presence of repeated nucleotide sequences which are longer than the sequence reads. Although alternative, long-read sequencing technologies exist which produce read lengths on par with the length of typical plasmids, current versions of the devices, and chemistry, are not sufficiently production-ready for Addgene. Since no publicly available, automated assembly pipeline exists which is able to overcome the difficulties of de novo sequence assembly for plasmids, Springbok worked with Addgene to explore how the problems caused by repeats for short-read assembly algorithms could be addressed. You can see some of our work on this project here.
I hope this short history increased your interest in synthetic biology. We are convinced that the developments here, coupled with developments in artificial intelligence, will be transformative in the coming decades.